
第6回 「別に、遅刻してもよくないですか?」Z世代が毎日遅刻し続けた結果……
2026.03.06
Z世代を甘やかすな
RAG関連で1万本以上の論文が書かれています。かように、RAGの実現方法、アレンジ法は様々です。中核部分だけをとってもても、一口にベクトル検索といっても、知識の実体をどのようにモデル化して、どのようなベクトル数値化するか千差万別の違いがあります。海外製の分かち書きツール、いわゆるトークナイザでは、日本語の単語、概念の単位を正しくとらえることができず精度が頭打ちになることもあります。あるドキュメントの目次の階層的な構造が知識体系を忠実に表現していることが多いですが、それを適切な粒度(サイズ)に切り取った知識素片(チャンクといわれます)が、知識体系全体の中でどのように位置づけられるかを適切にLLMに教える必要があります。こうした努力をすでに四半世紀前から行ってきている、いわば日本語処理職人の自分がまだまだ世のため人のため貢献できる度合いが大きそうだ。これが、「AI支援ナレッジマネジメント」という「昔の名前で出ています」と表明した理由です。
では具体的に、どう貢献すべきか。その最大のポイントが「精度(適合率 Precision)」です。世間では、「素のChatGPTでは精度が出ないのでRAGで正しく答えられるようにしましょう!」なる言い方が流布しています。これは厳密には間違いです。ここでいう精度は、検索結果の何%が正解かを問う「適合率 Precision」ではなく、これまで検索にひっかかってこなかったものをどれだけカバーできるようになったかを問う「再現率 Recall(カバレージ)」を意味するからです。
集合論の「ベン図」を使って描いた「適合率 Precision」「再現率 Recall(カバレージ)」を、往年の法政大学大学院イノベーションマネージメント研究科客員教授時代ならびに同志社大学ビジネススクールゲスト講師(2006-7)時代の講義資料から引用します:
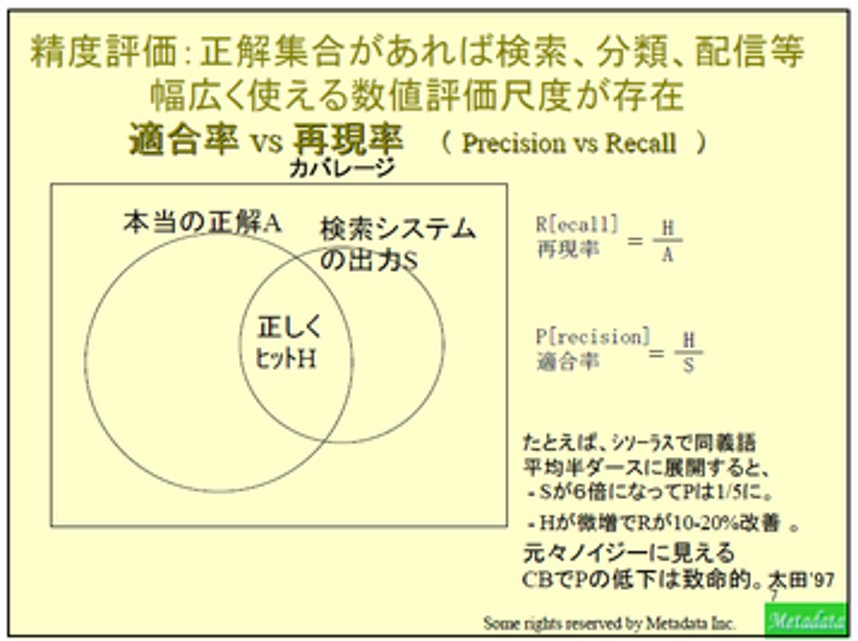
この図を使うと、両者の定義は実にシンプルに説明できます。例えば何かをテーマにした文書群を検索している状況で、社内なら社内の全文書の集合が図中の長方形、すなわち全体部分となります。その中で、神のみぞ知る(?)本当の正解、すなわちそのテーマの文書の集合が「本当の正解A」の円です。検索システム(やAI)が、これが正解でしょ? と出してきたのが「検索システムの出力S」の円です。この2つの円の交わり部分(intersection) が、「正しくヒットしたものH」となります。
「再現率 Recall(カバレージ)」とは、「本当の正解A」のうち何%を検索システムが拾えたかの数字ですので、H/A という割り算をするだけです。まさにカバー率ですね。「適合率 Precision」とは、「検索システムの出力S」のうち何%が正解だったかを示す数字ですので、 H/S? という割り算をするだけです。通常ユーザに見えるのはこちらだけであり、「精度」といったら本来こちらのことに他なりません。
ところが先の「素のChatGPTでは精度が出ないのでRAGで正しく答えられるようにしましょう!」なる言い方でRAGによって門外不出の社内知識をLLMが回答できるようになるというのは、本来の精度、「適合率 Precision」ではありません。新たに社内知識をカバーできるようになったから「再現率」が上がる、ということだけをさしているのです。
では精度はどうなるか? LLMには、適切に加工された正解データを大量に入れれば入れるほど精度が上がりました。しかしRAGの場合、似たり寄ったりの構成や内容の文書、バージョンが違って新旧、正誤入り混じった文書、もともと社員にとって当たり前の現場知識は省略されて書かれていなかったり日本語も目次構成も不備だらけだったりの文書など、入れれば入れるほど、どんどん精度が下がります。そもそも日本語の分かち書きや単語認定が間違っていたり、章立て、セクション分けに不備あったり、アウトライン無視した手動インデント(左から6つずつ各行に空白入れるなど)やエクセル方眼紙由来のPDFなどRAGシステムには酷なデータがたくさんあります。これらについて地道に数百種類の対策を行っていかないと90%以上の精度など望めないのが実情です(海外製トークナイザ=分かち書きのAPI頼りだと30~40%の精度しか出ないことがあります)。









