
第19回 さすがにキレてよし! なめられてムカついたときの正しい反撃の仕方
2025.11.12
なめてくるバカを黙らせる技術
デジタル法制を専門とする英国の競争法研究者は次のように指摘する。
「規制が参入障壁を高める逆説は珍しくない。データの有料化が進めば、既存の巨大プラットフォームこそが最も安定的なデータ調達力を持つ。新興勢力には、規制強化がむしろ競争上の不利として働くリスクがある」
今回の決算が明示するのは、グーグルのビジネスモデルが静かに、しかし構造的に変容しているという事実だ。
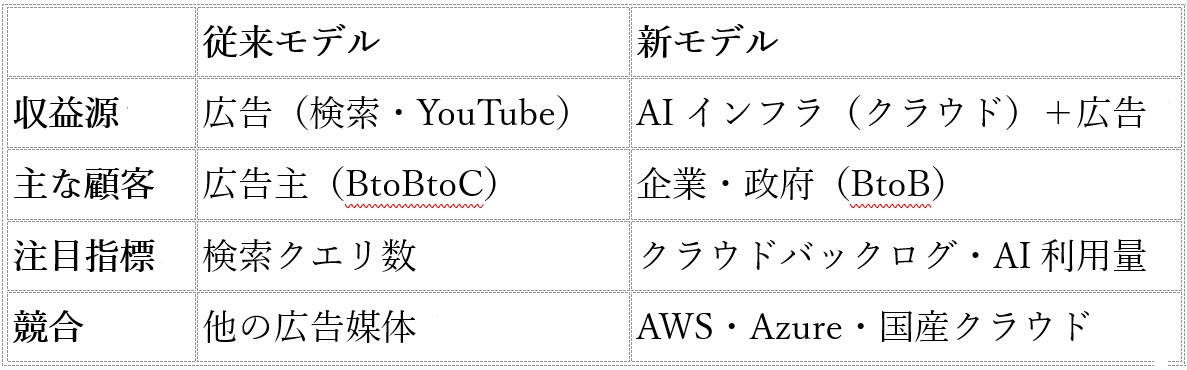
グーグルクラウドの営業利益はこの1四半期だけで66億ドルに達し、前年同期の9億ドル超から急拡大した。売上に占めるクラウドの比率も着実に上昇しており、広告依存からの脱却が財務数字にも表れてきた。
しかし見逃せないのが、設備投資(Capex)の規模だ。アルファベットは2026年通年の設備投資を1800〜1900億ドル(約28〜30兆円)と上方修正した(インターセクト社買収分を含む)。2025年の実績914億ドルから、ほぼ倍増する計算だ。Q1だけで357億ドルが投じられており、1四半期で日本の代表的な電機メーカー数社分の年間設備投資を超える額を使い果たす。
この投資規模は他のハイパースケーラーを凌駕する。アマゾン(約2000億ドル)とともにアルファベットは業界の基準値を塗り替えている。ピチャイCEO自身が「夜も眠れない問題」として挙げたのが、電力・土地・サプライチェーンのボトルネックだ。「今年はずっと供給制約の状態が続くと予想している」——この言葉は、需要がいかに旺盛かを裏返しで示している。
ITジャーナリスト・小平貴裕氏はこう評する。
「バックログが4600億ドルを超えたことは、企業のAI基盤としてのグーグルへの信頼を示している。だが年間設備投資が利益を大幅に超えるこのモデルは、成長が鈍化した瞬間に財務的な圧力が急増する構造的リスクを内包している」
規制当局の真の狙いは、もう一段深いところにある。
CMAが厳格に要求しているのは、「コンテンツのオプトアウトを選んだ出版社の検索順位を下げてはならない」という点だ。これは一見当然の消費者保護に見えるが、その本質はグーグルが検索でもつ支配的地位を、AIデータ調達の強制手段として使う慣行を断ち切ることにある。
現状のグーグルは、ウェブクローラーで収集したコンテンツをAIオーバービューや生成AIモデル(GeminiやVertex AI)の学習・グラウンディングに活用している。CMAは「グーグルの市場支配力があるがゆえに、出版社には事実上の拒否権がない」と指摘する。リサーチ会社Seer Interactiveの調査(2025年11月)によれば、AIオーバービューが表示された情報系クエリのオーガニックCTR(クリック率)は2024年半ば以降で61%低下しており、コンテンツ制作者の収益基盤を直撃している。
CMAの提案には「グーグルが第三者スクレイパーを通じてオプトアウト済みのコンテンツを迂回取得することも禁止する」条項も含まれる。これが実装されれば、グーグルの「AIインフラ地主」としてのコアな強みに、初めて実効性を持つ法的な歯止めがかかる。
「検索での支配力とAIでのデータ優位が連動している限り、規制の効果は限定的だ。この2つを制度的に切り離せるかどうかが、グーグルの市場構造に対する規制の真の試金石になる。EUがDMAでやっていることと同じ方向性だが、CMAのアプローチはよりデータの権利保護に焦点を当てている点で注目に値する」(小平氏)












